Publications
📑 Accepted Manuscripts
2025
VocQuiz: Vocabulary Question Generation for English Language Education
CIKM 2025 (Applied Research Track)
Yongqi Li, Jiajun Wu, Shangqing Tu, Jifan Yu, Huiqin Liu, Lei Hou, Juanzi Li
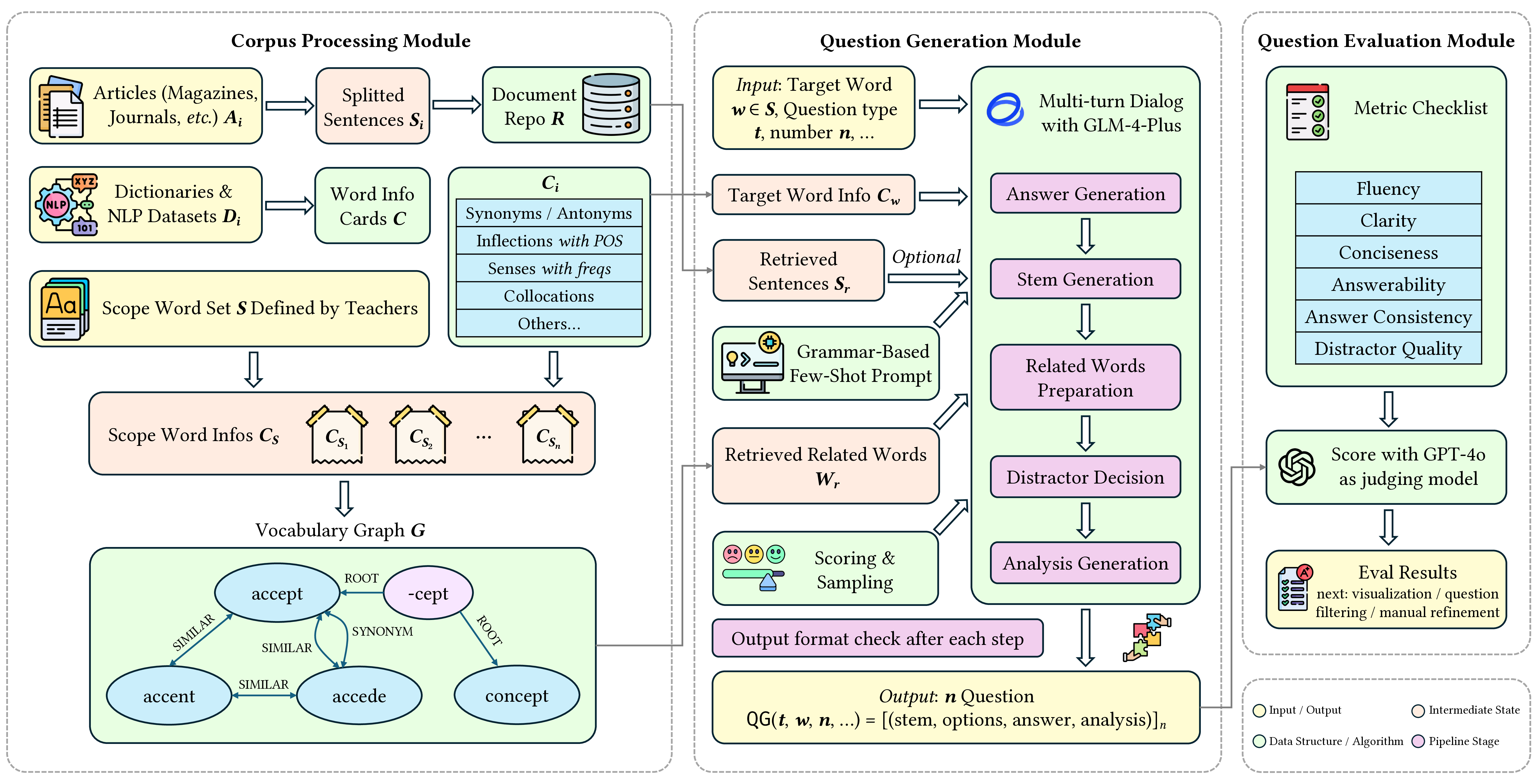
Designing effective English vocabulary question generation tools demands a shift from labor-intensive content creation to large language model (LLM) automation that can adapt to varied educational contexts. Current approaches tend to offer a limited variety of question types, which restricts their practical application in real classroom settings. To better meet the demands of English teaching institutions, we present
VocQuiz, a vocabulary question generation system that 1) combines generalization capabilities of LLMs with reliable language resources, including dictionaries, NLP datasets and authentic corpora, to enhance both contextual relevance and linguistic accuracy; 2) supports multiple question types, such as similar word selection and word collocation, to accommodate various instructional requirements; and 3) employs an iterative workflow to iteratively generate and refine questions, ensuring high-quality outputs and consistent assessment standards.VocQuizoffers a practical, deployable solution that helps educators create quiz-based instructional materials, reducing preparation effort while effectively assessing students' mastery of vocabulary.
📝 Submitted Manuscripts
2024
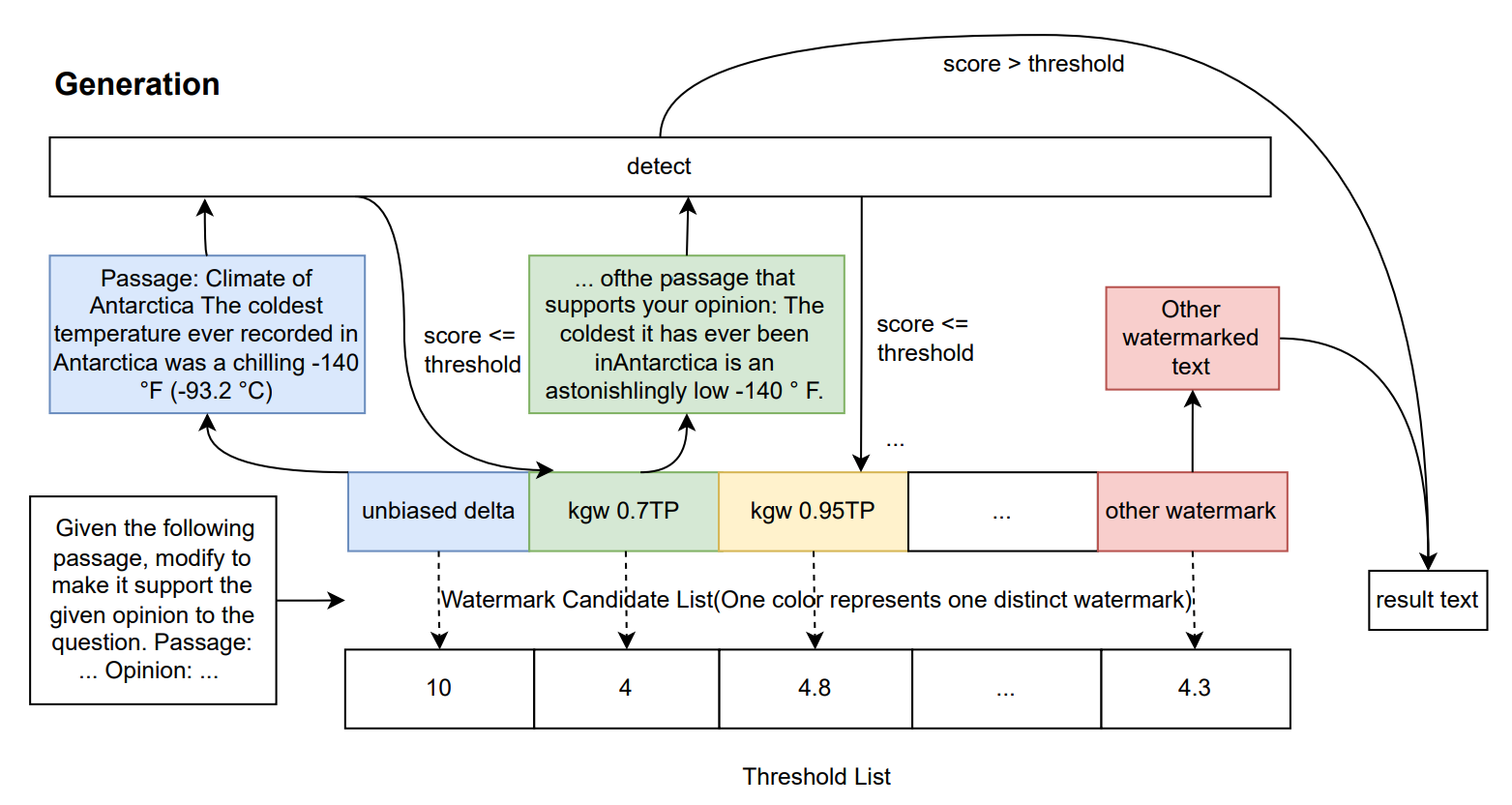
Detecting LLM Misinformation Pollution with Combined Watermark
ACL Rolling Review (October 2024)
Yuliang Sun, Shangqing Tu, Yongqi Li, Lei Hou, Juanzi Li, Irwin King
To mitigate the detrimental effects misinformation generated by Large Language Models (LLMs) has on Open Domain Question Answering (ODQA) systems that rely on retrieving knowledge from the web, we propose a novel combined watermarking scheme that leverages the strengths of two existing methods. One of them offers strong detectability but at the cost of generation quality, while the other preserves text quality but lacks detectability. By integrating both techniques, our approach maintains strong detectability without sacrificing text quality, thereby effectively reducing the impact of misinformation on downstream retrieval-based applications. We simulate an ODQA system pipeline, introducing 4 types of pollution methods, and incorporate our combined watermark into the reading process of the system to filter out the contaminated texts. Subsequently, we compare our method with baseline watermark methods on a watermark benchmark and evaluate the new watermark effect on the ODQA system. Our findings reveal that our new method ensures good text quality, with only an 8.8% decrease compared to the non-watermarked outputs, while maintaining strong detectability, resulting in nearly identical QA performance as without watermarking. This research provides a viable solution for maintaining the integrity of knowledge-intensive systems.